Podcast: Nano Banana to AI Phone_ Google’s Dual AI Strategy and Your Future Autonomy
Introduction: Decoding “Nano Banana” and the “Flash Image” Misnomer
In the rapidly accelerating landscape of artificial intelligence, a new model’s arrival is often heralded by a flurry of technical specifications and benchmark scores. Yet, occasionally, a technology transcends the developer community to capture the public imagination, propelled by a memorable codename and a tangible leap in capability. Such is the case with “Nano Banana,” the moniker that went viral on competitive AI evaluation platforms like LMArena before Google CEO Sundar Pichai officially confirmed its launch on August 26, 2025.1 This model, officially named
Gemini 2.5 Flash Image, represents a pivotal moment in the evolution of generative AI, marking a significant step forward in the quest for creative control and visual consistency.
However, the model’s official name introduces a critical point of semantic ambiguity that must be addressed at the outset. The query that brings many to this topic—”Gemini 2.5 flash image”—highlights a collision of specialized corporate branding with long-established technical jargon. For Google, “Flash” is a specific branding tier for a family of AI models meticulously optimized for speed, efficiency, and a lower cost-to-performance ratio, making them suitable for high-volume tasks.6 Conversely, in the world of embedded systems and hardware engineering, a “flash image” is a well-understood term for a complete binary file containing an operating system, applications, and data, designed to be written—or “flashed”—onto non-volatile flash memory chips like those found in everything from smartphones to industrial robots.10
This linguistic overlap is not merely a trivial detail; it reveals a broader communication challenge facing the technology industry. As AI penetrates deeper into technical and prosumer communities, naming conventions that are internally logical can create external confusion. The name “Gemini 2.5 Flash Image” is technically precise—it refers to the Image generation capability within the Gemini 2.5 Flash model family—but it is not immediately clear to an audience familiar with both AI branding and hardware terminology. This report will therefore proceed with the official name, Gemini 2.5 Flash Image, while acknowledging its viral codename, Nano Banana, to provide a comprehensive analysis. The launch of this model is far more than a simple product update; it is a meticulously calculated strategic move in the generative AI wars, representing a direct response to market pressures, a solution to long-standing technical hurdles, and a foundational pillar for the next generation of personal, context-aware computing.
1. The Generative Leap: Core Capabilities of Gemini 2.5 Flash Image
The excitement surrounding Gemini 2.5 Flash Image stems from its ability to solve some of the most persistent and frustrating problems in AI image generation. It moves beyond the probabilistic and often unpredictable nature of its predecessors to offer a suite of capabilities centered on control, consistency, and conversational creativity.
The Paradigm of Consistency: The Holy Grail of Generative AI
The model’s flagship feature, and the primary reason for its rapid ascent on leaderboards, is its state-of-the-art ability to maintain the identity of subjects—be they people, pets, or products—across a wide array of edits and entirely new scenes.1 This capability directly addresses a major pain point for users of previous-generation models, which often produced results that were frustratingly “close but not quite the same,” particularly when rendering faces or specific objects.17
This breakthrough in consistency was vividly demonstrated by Google CEO Sundar Pichai, who shared a series of images featuring his dog, Jeffree. The model successfully placed Jeffree in various imaginative scenarios—surfing, wearing a cowboy hat, and dressed as a superhero—all while preserving his distinct appearance.1 This is not a superficial trick; it signifies a deeper understanding of the core attributes of a subject, allowing the model to manipulate the context (background, clothing, action) without losing the subject’s identity. For creative professionals, marketers, and storytellers, this is a transformative capability. It enables the creation of coherent marketing campaigns with consistent product placement, the development of characters for storybooks or animations, and the generation of diverse brand assets that maintain a unified visual style.2
This advance in maintaining character identity is more than just a powerful enhancement for creative tools; it is a fundamental prerequisite for the next evolutionary stage of artificial intelligence: autonomous, agentic systems. Historically, image generators have been limited to creating disconnected, “one-shot” visuals. The ability to maintain a persistent subject across multiple outputs is the foundation of narrative. With this technology, a user can now generate an entire storybook with a consistent protagonist, create a multi-platform social media campaign with a unified look and feel, or even build a cohesive cinematic universe from a single character concept.18 Looking at the broader trajectory of AI development, where concepts like “agentic AI” and “multi-agent orchestration” are becoming central, this visual consistency is a critical component.21 An AI agent tasked with a complex, multi-step goal like “launch a marketing campaign for a new sneaker” can now autonomously generate a suite of visuals featuring that sneaker in various settings, on different models, and in multiple ad formats, all while ensuring perfect product consistency. This capability elevates the AI from a simple image generator to a potential creative director, laying the groundwork for the more sophisticated agentic functionalities anticipated in future models like Gemini 3.0.
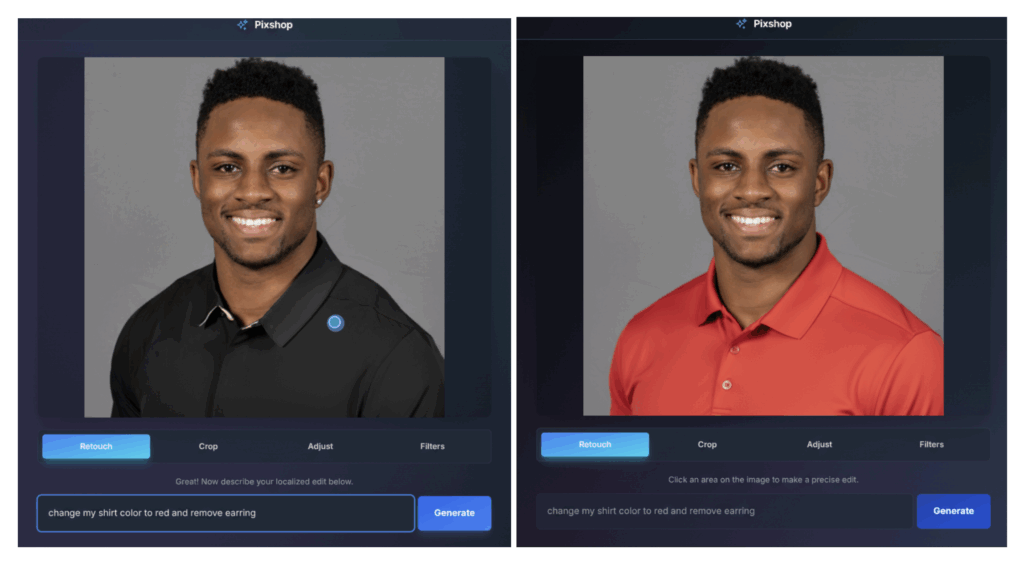
Conversational Creativity: Editing Through Dialogue
Gemini 2.5 Flash Image redefines the editing process by transforming it into a collaborative dialogue. The model supports multi-turn, prompt-based editing, allowing users to iteratively refine an image through simple, natural language instructions.16 This conversational loop treats the AI as a creative partner rather than a static tool. A user can upload a photo and begin a sequence of commands: “Turn this car into a convertible,” followed by, “Now change the color to yellow”.23
This paradigm extends to complex tasks that were previously the domain of professional editing software. Users can perform step-by-step interior design by adding or removing furniture, changing wall colors, and adjusting lighting in stages.17 This iterative process is made possible by the model’s low latency and its ability to preserve the scene’s semantics across multiple revisions, a key strength noted by early integration partners like Poe by Quora.16 This shift from a command-based interface to a conversational one democratizes advanced image manipulation, making it accessible to users without technical expertise in graphic design.
Intelligent Composition and Visual Reasoning
Beyond simple generation and editing, Gemini 2.5 Flash Image exhibits a deeper, more nuanced understanding of visual content, enabling advanced functionalities that blur the line between a tool and a creative collaborator.
- Multi-Image Fusion: The model can intelligently combine elements from multiple source images to create a single, seamless, and coherent new visual.16 This is particularly powerful for marketing and advertising, where it can be used to place multiple products into a single lifestyle shot or merge different campaign assets into a unified frame.16
- Style and Design Mixing: A user can provide one image as a source for texture or artistic style and another as the subject, instructing the model to apply the former to the latter. This could involve turning a floral pattern into a clothing design or applying the aesthetic of a famous painting to a personal photograph.2
- Visual Reasoning: The model’s capabilities extend beyond pixel manipulation to tasks that require genuine comprehension. It can analyze and solve hand-drawn mathematical equations, follow complex editing instructions that require an understanding of spatial relationships, and even restore old, damaged photographs by inferring the missing information.16 This demonstrates that the model is not just generating images based on text but is performing a form of visual reasoning, combining its vast world knowledge with the specific context of the input image.
2. Under the Hood: The Architecture Powering “Nano Banana”
The impressive capabilities of Gemini 2.5 Flash Image are not the result of a single breakthrough but rather the culmination of a vertically integrated strategy encompassing novel model architecture, bespoke hardware, and a built-in commitment to responsible deployment.
The “Flash” Philosophy: Speed, Efficiency, and Scale
The “Flash” designation in the model’s name signifies Google’s architectural approach to balancing performance with efficiency. Gemini 2.5 Flash Image is built upon a Sparse Mixture-of-Experts (MoE) architecture.26 In a traditional dense model, every parameter is activated to process every single input token, which is computationally expensive. In contrast, an MoE model consists of numerous smaller “expert” sub-networks. For any given input, a routing mechanism dynamically selects and activates only a small subset of these experts.
This design allows the model to decouple its total capacity (the total number of parameters) from the computational cost required for any single inference task.26 The result is a model that can possess a vast repository of knowledge and capability, comparable to much larger dense models, while maintaining the speed, low latency, and reduced cost necessary for high-volume, high-frequency applications like chat assistants, on-demand content generation, and real-time image editing.7 This architectural choice is the technical foundation of the “Flash” philosophy: delivering state-of-the-art quality at a significantly reduced cost and latency compared to monolithic Pro-tier models.7
Hardware Symbiosis: The TPU Advantage
The development and training of a model as sophisticated as Gemini 2.5 Flash Image are inextricably linked to the underlying hardware. The model was trained using Google’s proprietary Tensor Processing Units (TPUs), custom-designed silicon specifically engineered to accelerate the massive matrix computations inherent in training large neural networks.26
TPUs provide Google with a significant competitive advantage. Unlike general-purpose CPUs or even GPUs, TPUs are optimized for the specific workloads of machine learning, leading to considerable speed-ups in training time. They are typically equipped with large amounts of high-bandwidth memory and are deployed in large, scalable clusters known as “TPU Pods,” which allow for the efficient handling of foundation models with trillions of parameters.26 This deep, symbiotic relationship between Google’s model architecture and its custom hardware allows for faster iteration, more ambitious model designs, and an efficiency that is difficult for competitors relying on off-the-shelf hardware to replicate.
Responsible by Design: The Role of SynthID
A crucial technical component integrated into the model’s output pipeline is SynthID. This is Google’s proprietary technology for watermarking AI-generated content. It applies both a visible watermark (often a small logo) and, more importantly, an invisible digital watermark that is embedded directly into the pixels of the image.1 This invisible watermark is designed to be robust against common image manipulations like cropping, resizing, and compression, providing a persistent and verifiable signal that the content was generated by an AI.
The prominent inclusion of SynthID is not merely a technical footnote; it is a direct and strategic response to a significant political and public relations challenge Google faced earlier in the year. In March 2025, Google released its flagship model, Gemini 2.5 Pro, to considerable fanfare regarding its benchmark performance.28 However, the release was immediately met with a storm of criticism, most notably from over five dozen UK lawmakers. They accused Google DeepMind of violating international AI safety commitments by releasing the powerful model without concurrently publishing a detailed model card containing comprehensive safety testing information.29 The move was labeled a “troubling breach of trust with governments and the public” and created a significant trust deficit for the company.29
Viewed through this lens, the heavy and proactive emphasis on SynthID during the August 2025 launch of Gemini 2.5 Flash Image is clearly a calculated course correction. The messaging from Google and its partners was replete with references to responsible and transparent use, with SynthID positioned as a key enabler of this commitment.16 The technical feature of watermarking was thus deployed as a crucial tool for strategic reputation management, aiming to publicly demonstrate a renewed focus on safety and transparency to appease regulators, reassure enterprise partners, and rebuild trust with the public.
3. The Ecosystem Battleground: Market Positioning and Strategic Alliances
Gemini 2.5 Flash Image was not launched into a vacuum. Its release strategy reveals a sophisticated understanding of the modern technology landscape, where success is defined not just by a model’s standalone capabilities but by its deep integration into the workflows and platforms where users already exist.
The Alliance for Creativity: Beyond the Google Ecosystem
Recognizing that the world’s creative professionals are deeply embedded in established software suites, Google pursued a strategy of strategic alliances rather than attempting to build a walled garden. The model was launched with immediate, deep integrations into the industry’s most critical creative platforms. This includes Adobe Firefly and Adobe Express, placing Gemini’s capabilities directly within the workflows of millions of designers, marketers, and content creators.16 Similarly, an integration with
Figma brings the model’s power to the heart of the UI/UX design process.16
This approach is amplified by partnerships with innovative AI-native platforms like Poe by Quora, which leverages the model’s low latency for its real-time, conversational applications.16 By meeting developers and creators on their own turf, Google dramatically accelerates adoption and places its technology at the center of professional creative work, bypassing the monumental challenge of luring users away from their preferred tools.
The Enterprise Frontier: Vertex AI and the API Economy
In parallel with its consumer and creative-prosumer push, Google has positioned Gemini 2.5 Flash Image as a cornerstone of its enterprise AI offerings. The model is accessible in preview via Google Cloud’s Vertex AI platform, a comprehensive suite of tools that allows developers and businesses to build, deploy, and scale their own AI-powered applications.16 This dual-pronged strategy is crucial: it targets individual creators through third-party integrations while simultaneously empowering large-scale enterprise clients to build custom solutions on top of Google’s foundational technology. This API-first approach ensures that the model’s value extends far beyond Google’s own applications, fostering a vibrant developer ecosystem.
A Tale of Two Ecosystems: Google vs. Apple’s On-Device Intelligence
The launch of Gemini 2.5 Flash Image is best understood in the context of its primary competitor: Apple’s “Apple Intelligence” suite, which was the centerpiece of its 2025 Worldwide Developers Conference (WWDC).31 Apple’s approach to generative imagery, embodied by features like
Image Playground and Genmoji, presents a fundamentally different philosophy and technical architecture. A direct comparison reveals the strategic fault lines in the battle for the future of creative AI.
Table 1: Competitive Landscape of Generative Image AI (Q3 2025)
| Feature / Vector | Google Gemini 2.5 Flash Image (“Nano Banana”) | Apple Intelligence (Image Playground & Genmoji) |
| Primary Processing Model | Cloud-Hybrid: Leverages powerful server-side models via API for state-of-the-art quality and complex tasks.16 | On-Device First: Prioritizes a ~3B parameter on-device model for privacy, speed, and offline access. Uses “Private Cloud Compute” for more complex queries.33 |
| Core Capability | Character Consistency & Conversational Editing: State-of-the-art ability to maintain subject identity across complex, multi-turn edits.16 | Seamless OS Integration & Personalization: Deeply embedded into apps like Messages and Notes. Can create “Genmoji” that look like people in your photo library.33 |
| Editing Paradigm | Conversational & Iterative: Natural language dialogue to progressively refine images.23 | Tool-Based & Direct: Integrated as tools like “Image Wand” in Notes or features within the keyboard.33 |
| Ecosystem Integration | Professional Creative Suites: Deep integration with Adobe, Figma, and other third-party pro tools.16 | Consumer Operating System: System-wide integration across iOS, iPadOS, and macOS.31 |
| Developer Access | Open API: Accessible to all developers via Google AI Studio and Vertex AI API.16 | Proprietary Framework: Accessible to third-party developers via the new Foundation Models framework.31 |
| Marketing Strategy | Grassroots & Viral: Leveraged community hype from LMArena and a meme-able codename (“Nano Banana”).1 | Top-Down & Corporate: Branded under the unified, privacy-focused “Apple Intelligence” umbrella.33 |
The market is not witnessing a simple binary choice between cloud-based and on-device AI. Instead, the divergent strategies of Google and Apple reflect a pragmatic compromise rooted in a clear-eyed assessment of current technological trade-offs. While Apple’s marketing narrative heavily emphasizes its on-device, privacy-first philosophy, it implicitly acknowledges the limitations of this approach with its “Private Cloud Compute” system—a secure offloading mechanism for more complex tasks that cannot be handled locally.34 This is, in effect, a hybrid model, albeit one with a much higher threshold for cloud intervention than Google’s.
Google, meanwhile, offers its most powerful image model, Flash Image, as a primarily cloud-based service, while simultaneously developing a separate family of on-device “Nano” models to compete on Apple’s home turf.21 This reveals a strategic bifurcation. Google is betting that for high-end creative and professional applications, users will prioritize raw power, cutting-edge features like character consistency, and access to state-of-the-art models over the absolute privacy of on-device processing. Apple is betting that for the majority of everyday consumer tasks, the seamless OS integration, offline capability, and ironclad privacy guarantee of on-device AI are the paramount concerns. This is not a battle of pure ideologies but a strategic divergence based on a clear understanding of their respective target markets and the current realities of what is computationally feasible.
4. The On-Device Revolution: Contextualizing the “Nano” in Nano Banana
While Gemini 2.5 Flash Image primarily leverages the power of the cloud, its development and release are deeply intertwined with the broader, industry-wide shift toward edge computing and on-device AI. Understanding this macro trend is essential to grasping Google’s complete, multi-layered strategy.
The Inevitable Shift to the Edge
The migration of AI processing from centralized data centers to local devices is driven by a confluence of powerful incentives that address the fundamental limitations of a cloud-only model.
- Enhanced Privacy and Security: This is the most significant driver. By processing data locally, sensitive personal information—such as photos, messages, and biometric data—never has to leave the user’s device. This inherently mitigates the risks of large-scale data breaches, unauthorized surveillance, and the kind of data misuse that has fueled public concern.42
- Reduced Latency and Real-Time Processing: Eliminating the network round-trip to a cloud server enables instantaneous responses. This is not just a convenience; it is a critical requirement for applications like autonomous driving, real-time language translation, and augmented reality overlays, where even a millisecond of delay can be catastrophic.45
- Offline Capability: On-device AI ensures that core functionalities remain available even in areas with poor or nonexistent internet connectivity, a crucial feature for navigation apps, mobile productivity tools, and devices used in remote or rural settings.45
- Cost and Sustainability: Running inference locally reduces the massive operational costs associated with maintaining and powering vast data centers. For enterprises, this translates to lower server bills, and on a global scale, it helps lessen the significant carbon footprint of the AI industry.42
- Hyper-Personalization: An on-device AI has access to a rich, continuous stream of a user’s local data—their photos, contacts, calendar, location, and even sensor data from a smartwatch. It can learn from this data to provide deeply contextual, proactive, and personalized experiences without ever uploading that sensitive information to the cloud, thus resolving the tension between personalization and privacy.43
Navigating the Constraints
Despite its compelling advantages, the path to on-device AI is fraught with significant technical challenges. The computational resources of a smartphone, even a high-end one, are dwarfed by those of a cloud server. Key constraints include:
- Limited Compute and Memory: Running models with billions of parameters requires immense processing power and RAM, resources that are strictly limited on a mobile device operating within a tight power budget.47
- Energy Efficiency and Battery Drain: AI workloads are computationally intensive and can drain a device’s battery at an alarming rate. Engineers must employ advanced optimization techniques like quantization and pruning to reduce model size and energy consumption without severely degrading accuracy.46
- Hardware Fragmentation: Unlike the standardized hardware in a data center, the on-device ecosystem is a patchwork of different chips from Qualcomm, Apple, MediaTek, and others. A model optimized for one System-on-a-Chip (SoC) may not perform well on another, requiring extensive engineering effort to support a wide range of devices.47
These constraints explain why a hybrid approach is currently the most viable path forward. The most computationally demanding tasks, like the initial generation of a highly complex image with Gemini 2.5 Flash Image, are still best handled in the cloud, while other tasks like summarization or photo categorization can be run locally.
Google’s On-Device Play: The Gemini Nano Trajectory
Google is actively pursuing this hybrid strategy. While Flash Image represents the state-of-the-art in its cloud offerings, the company is simultaneously developing its Gemini Nano family of models, which are specifically designed to run efficiently on-device. Rumors and leaks point to the development of a powerful Gemini Nano 3 variant, potentially built for Google’s unannounced TPU v6 accelerators and designed to run a multi-billion parameter model directly on future Pixel devices.21 This would enable complex on-device tasks like real-time conversation summarization without a data connection, positioning Google to compete directly with Apple’s on-device intelligence capabilities.21 This parallel strategy allows Google to offer the best of both worlds: the raw power of the cloud via its Flash and Pro models, and the privacy and efficiency of the edge via its Nano models.
The Ethical Dimensions of Pervasive AI
As powerful AI models migrate from remote servers onto the devices we carry in our pockets, a new set of nuanced ethical considerations emerges. While on-device processing enhances privacy by keeping data local, it does not eliminate all risks. The potential for on-device AI to continuously monitor user activity, even for benign personalization purposes, raises questions about surveillance and user autonomy.44 Algorithmic bias, learned from training data, can still lead to discriminatory outcomes, whether the model runs in the cloud or on a device.48 Furthermore, the power to generate hyper-realistic images and deepfakes directly on a phone, untethered from a central server, creates new avenues for misuse.49 Addressing these challenges requires a multi-faceted approach that goes beyond technical solutions, encompassing robust transparency about what data is being collected and how it is used, clear user controls to opt-out of AI processing, and the development of strong ethical guidelines and regulatory frameworks to govern this new era of pervasive AI.50
5. The Road Ahead: From Flash Image to the “AI Phone” Era
The launch of Gemini 2.5 Flash Image is not an endpoint but a significant milestone on a much longer strategic roadmap. By synthesizing credible industry speculation, code commits, and the stated visions of key players, it is possible to sketch a compelling picture of where Google’s AI strategy is headed and how it will shape the future of personal technology.
Reading the Tea Leaves: The Path to Gemini 3.0
The AI industry operates on a rapid development cycle, and even as the 2.5 series of models is being rolled out, attention is already turning to the next major iteration. Credible leaks, rumors, and even references found in Google’s own code repositories point toward the development of Gemini 3.0, with a potential release window in late 2025 or early 2026.21 The anticipated features of this next-generation model suggest a qualitative leap in capability:
- “Deep Think” as a Core Capability: The “Deep Think” mode introduced in the 2.5 series, which allows the model to vet its own answers and perform more complex reasoning, is expected to be fully integrated into the core of Gemini 3.0. This would eliminate the need for a separate mode, making advanced reasoning, self-correction, and multi-step planning a default behavior.21
- True Real-Time Multimodality: Gemini 3.0 is expected to move beyond static modalities to handle dynamic, real-time data streams. This includes the ability to understand and process live video at up to 60 frames per second, comprehend 3D objects, and interpret geospatial data, features that would revolutionize applications in augmented reality, robotics, and real-time assistance.21
- Dynamic Mixture-of-Experts: The MoE architecture is rumored to evolve significantly. A system, potentially codenamed “Conductor,” could intelligently assemble a bespoke combination of expert sub-models on the fly, tailored to the specific complexity of a given query. This would allow the model to feel incredibly fast for simple tasks while engaging its full power—potentially in the low single-digit trillions of parameters—for complex reasoning, solving the latency issues that have plagued earlier MoE models.21
The Dawn of the “AI Phone”
These technological advancements are not being developed in isolation; they are the foundational building blocks for a new computing paradigm that partners like Samsung are calling the “AI Phone”.56 This concept represents a fundamental shift from the current smartphone era. An “AI Phone” is not merely a device that has AI features bolted on; it is a device where AI is the core operating platform.
In this vision, the AI acts as a proactive, personalized, and context-aware assistant, deeply integrated into every facet of the device’s operation. It will anticipate user needs, automate complex multi-app workflows, and provide information and assistance based on a deep, privacy-preserving understanding of the user’s context. Models like the cloud-powered Gemini 2.5 Flash Image and the on-device Gemini Nano 3 are the essential components that will make this vision a reality. The cloud provides the raw intelligence for complex planning and generation, while the on-device model handles the real-time, privacy-sensitive tasks of understanding the user’s immediate environment and personal data.
Concluding Analysis: A Decisive Move in the AI Wars
The release of Gemini 2.5 Flash Image, known colloquially as Nano Banana, should be viewed as a highly successful and decisive strategic maneuver by Google. It effectively counters the narrative from competitors by re-establishing Google’s leadership in the critical domain of generative image quality and control, particularly through its breakthrough in character consistency.
More importantly, the launch reveals a comprehensive, multi-front strategy for dominating the next era of AI. By simultaneously pushing the state-of-the-art in the cloud with its Flash and Pro models, developing a robust and competitive on-device strategy with its Nano family, and fostering a powerful developer and partner ecosystem through Vertex AI and strategic alliances with companies like Adobe, Google is ensuring it has a formidable presence at every layer of the AI stack. “Nano Banana” is therefore far more than just a powerful and entertaining creative tool; it is a clear and unambiguous signal of Google’s intent to provide the core intelligence that will define the next generation of computing.